从源码的角度简单总结ThreadPoolExecutor线程池的实现原理。
Executor
java.util.concurrent包里负责处理线程池的接口。
Executor是一个执行Runnable任务的接口,只有一个execute方法。这个接口将任务的提交工作从任务执行中解耦出来。Executor通常用来代替显示地创建线程。
1 | public interface Executor { |
ExecutorService
ExecutorService接口继承自Executor,提供了管理线程生命周期的方法,可以返回一个Future对象来跟踪异步任务的执行过程。比如shutdown方法可以让它拒绝新的任务;submit方法是基于Executor的executor方法的,接收Runnable或Callable任务,可以创建并返回一个Future对象,通过Future对象可以强制取消或让任务挂起。
Executors
主要提供一系列工厂方法创建线程池,返回的线程池都实现了ExecutorService接口。主要有三种
- CachedThreadPool:创建一个可缓存的线程池,一个任务创建一个线程;
- FixedThreadPool:创建固定数目线程的线程池
- SingleThreadExecutor:相当于大小为 1 的 FixedThreadPool。
这三种线程池都是ThreadPoolExecutor的实例。
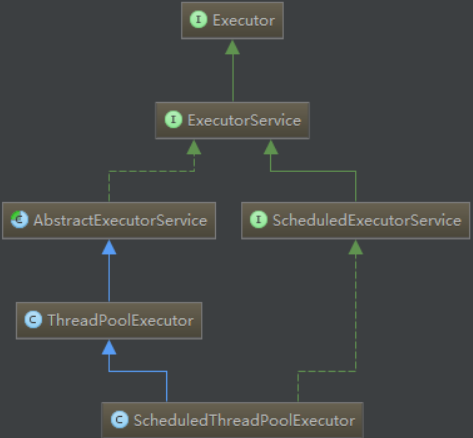
ThreadPoolExecutor
ThreadPoolExecutor这个类是我们这篇文章的核心,上一节提到的三种线程池实际上都是特殊的ThreadPoolExecutor。Executors类中三个创建线程池的静态方法都返回了ThreadPoolExecutor实例,区别仅在于参数的不同。所以我们应该把注意力放到ThreadPoolExecutor上。
1 | //Executors.java |
ThreadPoolThread对象的构造方法如下:
1 | public ThreadPoolExecutor(int corePoolSize, |
每个参数的含义都有官方解释:
- corePoolsize:线程池有多少条线程,即使他们是闲置的
- maximumPoolSize:线程池所允许存放线程的最大数量
- keepAliveTime:当线程池线程的数量超过了corePoolSize,那些额外闲置的线程所能存活的时间
- unit:keepAliveTime时间的单元粒度
- workQueue:阻塞队列,存放即将被执行的任务
- threadFactory:executor创建线程时使用的线程工厂
- handler:线程池拒绝策略处理器。当线程池线程已满或阻塞队列已满时拒绝新的任务请求。
我们使用线程池一般通过如下方法:
1 | ExecutorService executorService = Executors.newFixedThreadPool(2); |
第一行实际上就是返回了一个ThreadPoolExecutor的实例,然后调用execute方法,所以关键在于这个方法内部 。
1 | public void execute(Runnable command) { |
首先我们看一下这个ctl是什么,它是一个原子操作的整型,用来描述线程池的控制状态,包装了两个概念域
- workCount:有效线程的数量,指已经开始运行且不被允许停止的线程的数量,可能不等于真实存活的线程的数量。
- runState:线程在运行还是关闭等状态
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
所以第一步是根据ctl的状态判断正在运行的线程数是否小于核心线程数,如果满足则尝试创建一个新核心线程,并把当前任务分配给它执行。
第二步尝试把任务加入阻塞队列,如果这时线程池没有运行,就移除任务并执行拒绝策略;如果线程池还在运行,就说明没有可用的线程了,就启动一个线程。
第三步如果无法把任务加入阻塞队列,就尝试创建一个新的非核心线程,如果失败,就直接执行拒绝策略。
addWorker
根据上面的介绍,我们知道addWorker方法是是用来创建线程并执行任务的。
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
在try代码块内执行创建线程的操作。ThreadPoolExecutor把执行任务的线程封装为一个Worker对象,我们看Worker类的定义可以发现,它实现了Runnable接口并继承了AQS!
1 | private final class Worker |
所以先创建线程,然后添加到线程池中,最后再启动线程。那么线程池workers是什么呢?
1 | /** |
可以看到workers是一个HashSet,也就是说线程池底层的存储结构就是一个HashSet,存储工作线程Worker!
runWorker
工作线程启动后或调用Worker的run方法,run实际上是交给了runWorker方法进行处理。
1 | final void runWorker(Worker w) { |
getTask()是从队列中获取任务。
可以看到任务执行之前和任务执行之后有两个方法,beforeExecute和afterExecute,他们本身是protected类型的空方法,是允许我们继承线程池,自定义任务执行前后的操作。
reject
当队列已满且线程池中线程的数量也达到了最大值,再有新任务进来就会触发线程池的拒绝策略。
ThreadPoolExecutor提供了几种拒绝策略的实现类。
- AbortPolicy
1 | public static class AbortPolicy implements RejectedExecutionHandler { |
默认的拒绝策略。直接抛出RejectedExecutionException异常。
- DiscardPolicy
1 | public static class DiscardPolicy implements RejectedExecutionHandler { |
直接抛弃这个任务什么都不做。
- DiscardOldestPolicy
1 | public static class DiscardOldestPolicy implements RejectedExecutionHandler { |
根据名称,抛弃最老策略,就是把队首元素抛弃。
- CallerRunsPolicy
1 | public static class CallerRunsPolicy implements RejectedExecutionHandler { |
调用者主线程直接执行。
总结
- ThreadPoolExecutor默认使用核心线程处理任务
- 工作线程数等于核心线程数时,新来的任务加入阻塞队列
- 阻塞队列任务已满,开始创建非核心线程处理任务
- 线程池线程的数量达到maximumPoolSize时,执行拒绝策略
- ThreadPoolExecutor底层数据结构是HashSet